
Medidas de Centralidad y Dispersión
Para la discusión de este tema, usemos un ejemplo donde a cien pacientes hipertensos se les prescribe un agente antihipertensivo. Para evaluar la eficacia del tratamiento, se toman registros de la PA antes y después del tratamiento. Una forma de informar la eficacia del tratamiento sería enumerar en una tabla los PA de todos los sujetos antes y después del tratamiento. Evidentemente, sería extremadamente difícil para un observador evaluar si el tratamiento ha tenido éxito. La suma de todos los valores de PA antes del tratamiento y la división por el número de observaciones proporcionaría un valor medio para la PA antes del tratamiento; se podría hacer lo mismo para el postratamiento. En lugar de listas largas, solo tendríamos que comparar dos valores. Los promedios antes y después del tratamiento podrían compararse y evaluarse si la diferencia era significativa.
Media y mediana
En general, “el promedio” se expresa en términos estadísticos ya sea por la media o la mediana (hay otras medidas del centro que podemos ignorar por ahora). La media es el promedio aritmético, la suma de todos los valores dividida por el número de observaciones. La mediana es el valor que separa el 50% superior de sujetos del 50% inferior. Para comprender la diferencia entre media y mediana, primero debemos examinar el concepto de normalidad de distribución.
Figura 1 Distribución de los pesos corporales de más de 700 pacientes en diálisis (barras) y la frecuencia porcentual acumulada (línea)
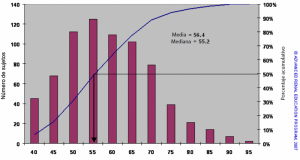
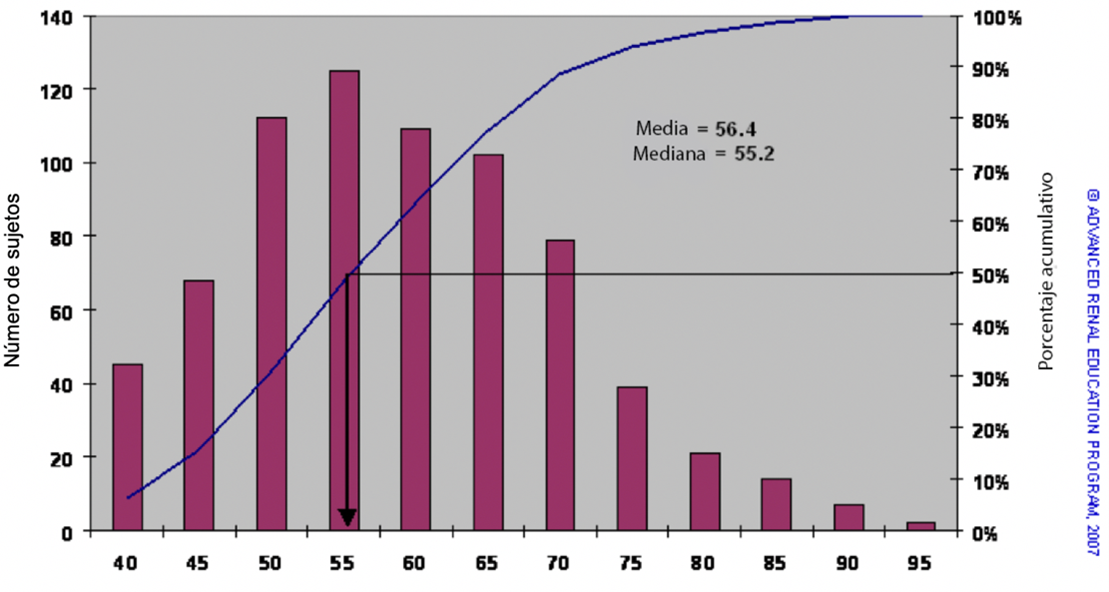
La Figura 1 muestra un histograma de la distribución de los pesos corporales de más de 700 pacientes en diálisis (barras) y la frecuencia porcentual acumulada (línea). Imaginar una línea trazada a través de los puntos superiores de las barras produciría una curva en “forma de campana”; los datos que tienen este tipo o distribución se denominan distribuciones normales. Podemos calcular la media (suma de todos los valores dividida por el número de observaciones) y encontrar el valor 56,4 kg. Para encontrar la mediana, determinamos el valor del peso que divide a la población en dos mitades iguales, como lo muestra la flecha que desciende de la línea de frecuencia acumulada; el valor real es de 55,2 kg. Normalmente, para estos datos distribuidos normalmente, la mediana y la media son muy similares.
Figura 2. La población de arriba que incluye un pequeño número de pacientes con alto peso corporal.
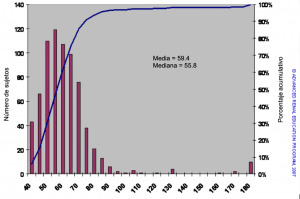
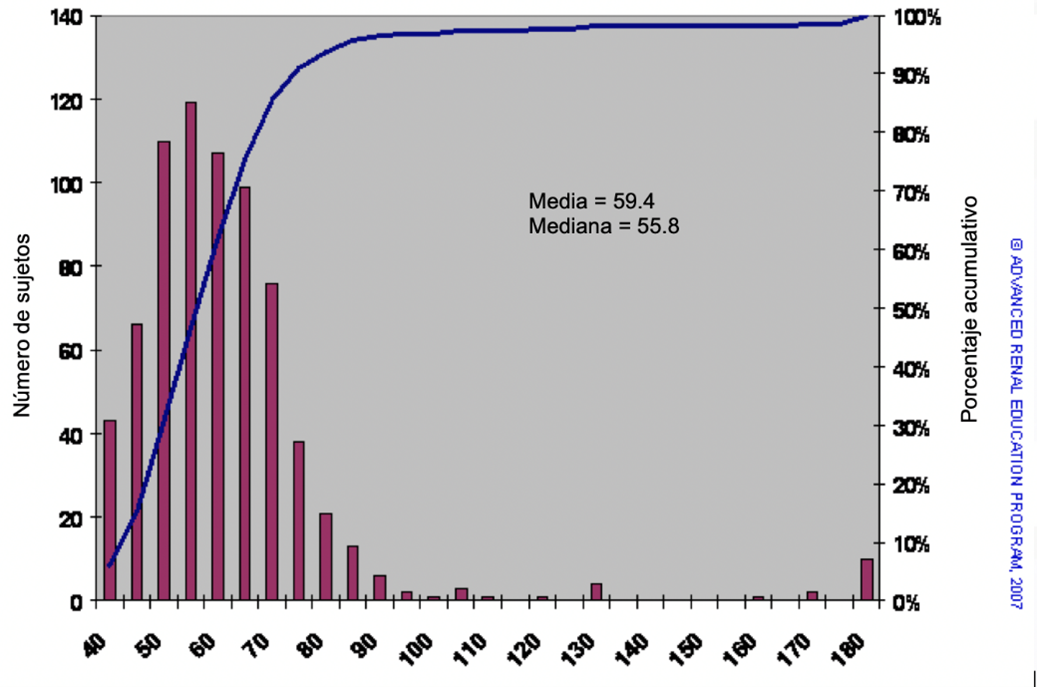
En la Figura 2, la población es casi la misma, pero incluye un pequeño número de pacientes con pesos corporales extremadamente altos.
Nuevamente, podemos estimar los pesos medio y mediano. La adición de los pacientes más pesados, aunque pocos en número, tiene un efecto significativo para aumentar el peso medio (en 3 kg) pero tiene poco efecto sobre la mediana. La mediana se ve poco afectada por valores atípicos extremos, mientras que la media es sensible a ellos. El conocimiento de cómo se distribuye un conjunto de datos indica qué medida de centro es más apropiada.
Dispersión sobre el centro1
Aunque las medidas de centro brindan información resumida útil sobre un conjunto de datos, no nos dicen nada sobre cómo se dispersan los datos. Una forma de indicar la dispersión de datos sería informar el rango de valores de datos: el más bajo y el más alto. En la Figura 1, los pesos oscilan entre 19,94 y 94,8 kg, por lo que el conjunto de datos podría resumirse informando la mediana y el rango como 55,2 (rango: 19,4 94,8). Para el conjunto de datos de la Figura 2, el informe sería 55,8 (rango: 19,94-180).
Otras medidas de dispersión son la varianza y la desviación estándar (DE: = Övarianza). La varianza y la DE se calculan a partir de fórmulas estadísticas estándar. Para ilustrar esto, usaremos dos conjuntos de datos como se muestra en la tabla.
Los conjuntos de datos son bastante similares excepto que el Conjunto 2 incluye 2 valores extremos más. Podemos ver el efecto de estas diferencias expresando la media, la varianza y las desviaciones estándar de las dos series:
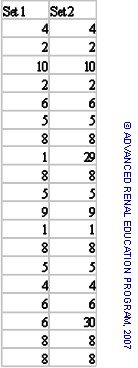

Tenga en cuenta el signo ± antes de la SD; esto indica la dispersión de valores por encima y por debajo de la media.
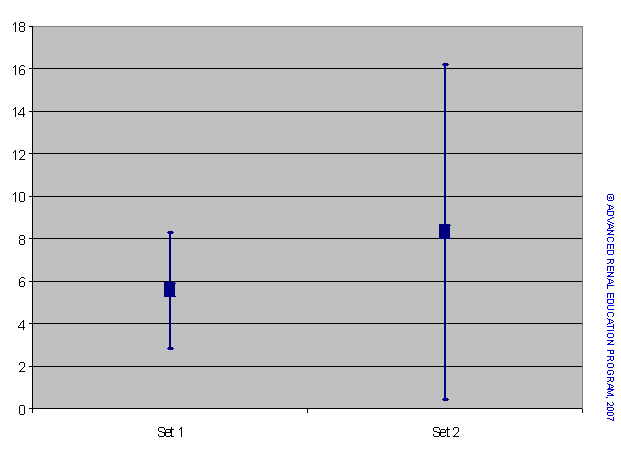
La mayor varianza y desviación estándar del Conjunto 2 indican una mayor dispersión de los datos alrededor de la media que para el Conjunto 1. La varianza es muy importante cuando se comparan las medias de dos o más conjuntos de datos. Las medias y la DE se muestran en forma gráfica en la Figura 3.
Recursos:
Dawson B, Trapp RG. Chapter 8. Research Questions About Relationships among Variables. In: Dawson B, Trapp RG, eds. Basic & Clinical Biostatistics. 4th ed. New York: McGraw-Hill; 2004.
Walters RW, Kier KL. Chapter 8. The Application of Statistical Analysis in the Biomedical Sciences. In: Kier KL, Malone PM, Stanovich JE, eds. Drug Information: A Guide for Pharmacists. 4th ed. New York: McGraw-Hill; 2012.
Godfrey K. Chapter 6. Testing for Relationships, Reporting Association and Correlation Analyses. In: Lang TA, Secic M, eds. How to Report Statistics in Medicine. 2nd ed. Philadelphia: American College of Physicians; 2006.
P/N 101880-01S Rev B 02/2023